A private foundation was approaching one of its first grant cycles. Applications had arrived covering the full range: large national organizations, small regional shops, policy institutes, classical schools. Each submission included narrative responses to four open-ended questions, organizational background, financial statements, audits, and tax filings. The board meets on a fixed schedule. The review window was short and the foundation did not have staff to do multi-reader evaluation at scale. Months of reading, calibrating, and debating would be the traditional path. The foundation's administrator asked a different question: could an AI-led process produce the same quality of analysis, faster?
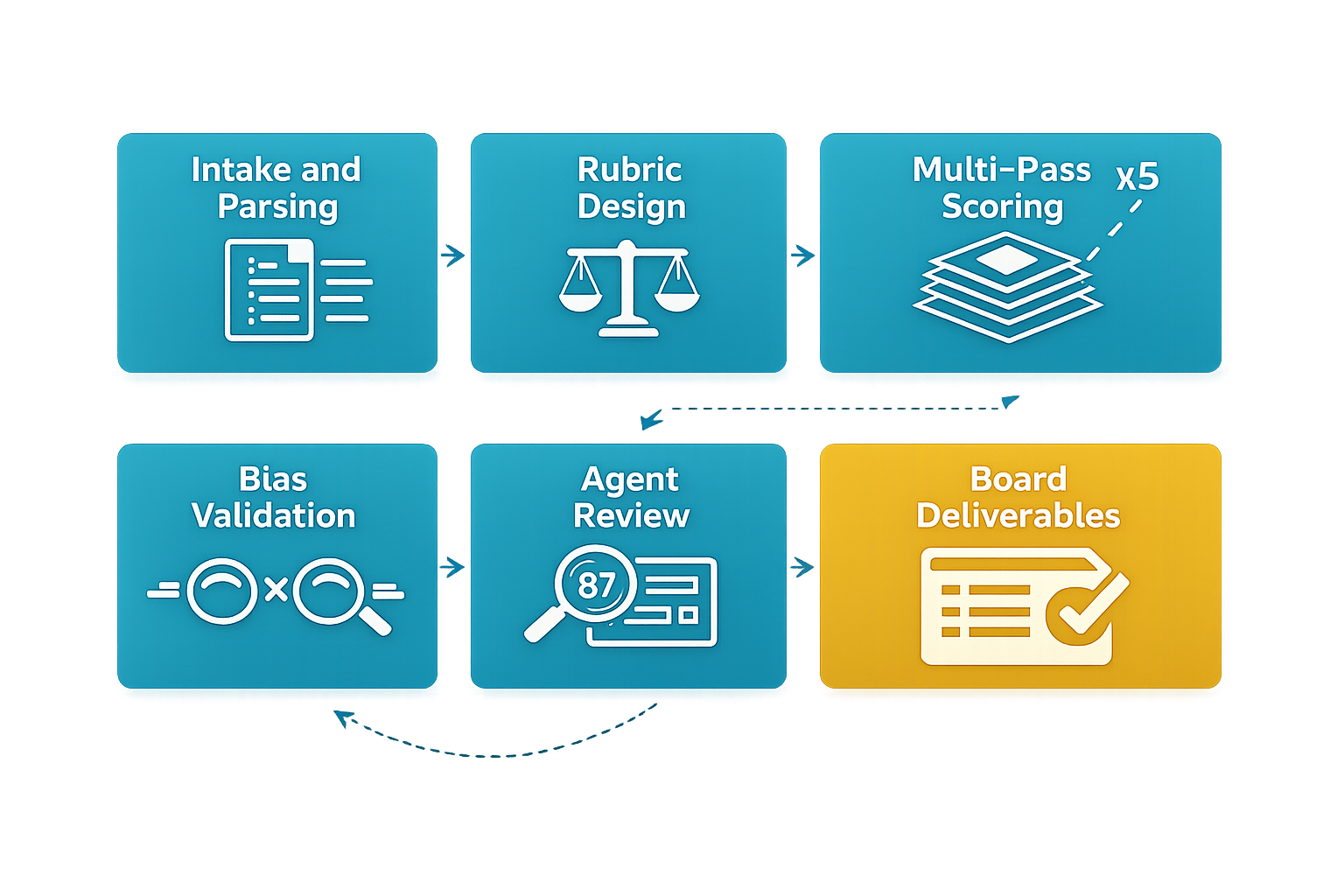
Applications arrived as unstructured documents. PDFs with narrative text, financial attachments, supporting materials, all in different formats and levels of completeness. The first job for the agent team was ingestion: parsing every submission, extracting structured data from the narratives and financials, and refactoring everything into a normalized database. Every applicant reduced to the same schema. Clean, comparable inputs for everything downstream.
This is unglamorous work, but it is where most evaluative processes stall. A human reviewer reading forty PDFs of varying quality and format burns days just getting oriented. The agents did it systematically, flagging gaps (missing audits, incomplete financials) as they went.
The evaluation framework was designed around the foundation's stated values and priorities, not a generic nonprofit checklist. Six weighted criteria: mission alignment, organizational capacity, program design, projected outcomes, financial health, and risk posture. The weights were calibrated through analysis of the foundation's philosophy, its application form structure, and benchmarking against peer foundations' evaluation practices.
"For a young foundation, funding the wrong organization is a bigger risk than passing on a good one. The rubric encoded that judgment."
Mission alignment and risk/compliance received the heaviest weights. That was a deliberate design choice, and it shaped everything downstream.
Each application was scored across multiple independent rounds. Not once. Not twice. Five full passes per applicant, per methodology. Why? Because any single AI evaluation has variance.
"A score produced once is an opinion. A score produced five times, with outliers trimmed and the middle averaged, is a measurement."
A second scoring variant introduced additional controls: identity-blind assessment, size-aware calibration, and explicit bias minimization. This gave the board two lenses to compare and increased confidence that the rankings were not artifacts of a single prompting approach.
Scoring agents were then evaluated by other agents. A judge-of-judges layer examined individual scorecards for internal consistency, flagged anomalies in the reasoning, and produced confidence-weighted final rankings. Where scores diverged across passes, the review layer investigated why and annotated the finding.
"The agents did not just execute a rubric. They audited each other's work."
This is the pattern that distinguishes agent orchestration from simple automation. The same principle applies whether you are reviewing grant applications, evaluating vendor proposals, or scoring RFP responses.
The output was not a spreadsheet. The agent team produced the full board packet: an executive summary with methodology justification, detailed scorecards with criterion-level narrative for every applicant, category-segmented rankings, a red-flag taxonomy identifying financial or compliance concerns, and an interactive assistant the trustees could use to interrogate any submission conversationally.
Everything the board needed to walk into their meeting prepared. Not a data dump requiring interpretation, but analyzed, annotated, and structured for decision-making.
What would normally take multiple reviewers several months of reading, calibrating, and debating was completed in roughly one week by one consultant and an agent team. The board received scored, ranked, and annotated recommendations with full audit trails. They also received something no traditional review process provides: a tool to ask follow-up questions about any applicant on the spot.
The engagement demonstrated that agent orchestration is not limited to building software or writing content. It applies directly to professional judgment tasks, the evaluative, analytical work that organizations pay senior people to do slowly. The method is repeatable, the scoring is auditable, and the timeline compresses by an order of magnitude.